RESOURCE
Blog Series - Part 3: Code-level optimization techniques
Blog Series: Optimizing Java Performance: A Deep Dive into Memory Management
August 6, 2024

**This article is the final installment in our 3-part series on "Optimizing Java Performance: A Deep Dive into Memory Management" written by our Software Developer, Katsiaryna Auchynnikava.
ENGIN™, an asset analytics accelerator, provides utility asset management planners with a powerful tool to gather the insights they need for their entire power system. ENGIN™ accelerates all the analytical workflows required for planning, and models the system of interconnected assets, from generating source to customer load that brings forward the intel that utilities need to make better business decisions.
Java continues to be a cornerstone in enterprise-level and large-scale application development, and is one of the core technologies used within our application. Achieving optimal performance and efficient memory management remains crucial as users expect applications to be fast, responsive, and reliable. Performance optimization and memory management are not just about making applications run faster; they are about ensuring stability, reducing costs, and improving the overall user experience.
Introduction
In our previous blog, we discussed key metrics for garbage collection and how to optimize your Java application's performance by tuning these metrics. Today, we will focus on code-level optimization techniques, including efficient data structures, minimizing object creation, and optimizing loops and iterations.
Efficient Data Structures
Data structures are fundamental to Java applications, and their choice can significantly impact performance. The right data structure can optimize memory usage, improve execution speed, and enhance overall application efficiency. Conversely, an inappropriate data structure can lead to increased memory consumption, slower operations, and degraded performance. Key factors influencing performance are time complexity, space complexity and operation frequency.
Time Complexity: Different data structures have varying time complexities for common operations such as insertion, deletion, search, and access. Understanding these complexities helps in selecting the most efficient data structure for a given task.
Space Complexity: The amount of memory required by a data structure also varies. Efficient memory usage is crucial for applications with limited resources or those running in environments where memory is a critical factor.
Operation Frequency: The frequency and type of operations performed on the data structure can influence performance. For example, if frequent insertions and deletions are required, a data structure optimized for these operations should be chosen.
Array List vs. LinkedList
1. Array List
- Access Time: Constant time complexity O(1) for random access, as elements are indexed.
- Insertion/Deletion: Inserting or deleting elements (except at the end) involves shifting elements, leading to O(n) complexity.
- Memory Usage: Arrays have a contiguous block of memory, which can be efficient but may lead to memory waste if the array is sparsely populated or if frequent resizing is needed.
2. Linked List
- Access Time: Linear time complexity O(n) for random access, as it requires traversal from the head.
- Insertion/Deletion: Efficient at O(1) if the position is known, since it involves only pointer updates.
- Memory Usage: Each element has additional overhead due to storing pointers (references) to the next (and possibly previous) elements, leading to higher memory consumption.
HashMap vs. TreeMap
1. HashMap
- Access Time: Average time complexity O(1) for get and put operations, due to hashing.
- Insertion/Deletion: Average O(1), but can degrade to O(n) if many elements hash to the same bucket.
- Memory Usage: Efficient in terms of memory, but depends on the load factor and initial capacity. Overhead includes storing the hash table and linked list of entries in each bucket.
2. TreeMap
- Access Time: Logarithmic time complexity O(log n) for add, remove, and contains operations.
- Insertion/Deletion: O(log n) due to tree rebalancing.
- Memory Usage: Higher due to maintaining the tree structure.
Priority Queue
- Access Time: Logarithmic time complexity O(log n) for insertion and O(1) for access to the minimum or maximum element.
- Insertion/Deletion: O(log n) for insertion and removal operations.
- Memory Usage: Efficient for priority operations, but elements are not ordered linearly like in a list.
Selection of the Right Data Structure:
Access Patterns:
- Use ArrayList for scenarios requiring fast random access.
- Use LinkedList for scenarios with frequent insertions/deletions at the start or middle.
Key-Value Pairs:
- Use HashMap for fast access with no need for order.
- Use TreeMap for ordered key access.
Sets:
- Use HashSet for fast access without order.
- Use TreeSet for ordered elements.
Queues:
- Use PriorityQueue for elements requiring priority ordering.
Primitive Types vs. Wrapper Classes
Memory Consumption:
- Primitive Types: Use a fixed amount of memory. For example, an int uses 4 bytes, while a double uses 8 bytes.
- Wrapper Classes: Consume additional memory for object overhead. For example, an Integer object contains not only the int value but also object metadata.
Execution Speed:
- Primitive Operations: Arithmetic and logical operations on primitives are performed directly by the CPU, leading to faster execution.
- Wrapper Class Operations: Involve additional steps due to object creation, garbage collection, and method calls.
Autoboxing and Unboxing:
- Autoboxing: Automatic conversion of a primitive type to its corresponding wrapper class. For example, converting int to Integer.
- Unboxing: Automatic conversion of a wrapper class to its corresponding primitive type. For example, converting Integer to int.
- Overhead: These conversions add computational overhead and can degrade performance, especially in loops and high-frequency operations.
Best Practices:
- Use primitive types for local variables, loop counters, and simple arithmetic operations.
- Be mindful of situations where autoboxing and unboxing might occur. Avoid using wrapper classes in high-frequency operations and performance-critical code.
- Use primitive-specific streams (e.g., IntStream, LongStream) and Optional classes (e.g., OptionalInt, OptionalLong) to avoid boxing overhead.
Optimizing Loops and Iterations
Optimizing loops and iterators is crucial for enhancing Java application performance. By making loops more efficient and selecting the right iteration techniques, you can significantly reduce execution time and resource consumption. Here are some best practices and strategies for optimizing loops and iterators:
1. Minimize Loop Overhead
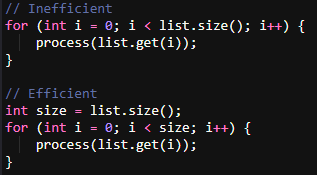
In this example, list.size() is called in every iteration, adding unnecessary overhead. Solution: cache the size of the list before the loop to avoid repeated method calls.
2. Use the Enhanced for Loop for Collections
Example of inefficient loop:
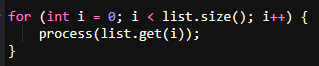
This loop involves indexing, which can be less efficient for certain collection types (e.g., LinkedList).
Optimized loop:
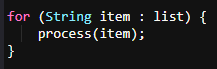
Use the enhanced for loop, which is more readable and efficient, especially for collections like LinkedList.
3. Use Stream API and Lambda Expressions. Leverage Java 8 features for concise and efficient code.
4. Avoid creating unnecessary objects in the Loops
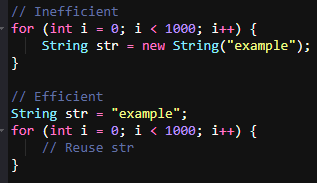
Creating a new String object in every iteration consumes memory and CPU resources. Move object creation outside the loop to reuse the object and save resources.
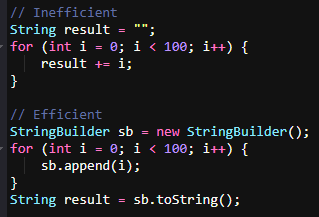
5. Use StringBuilder for String Concatenation in Loops
String is an immutable object, every change on each iteration triggers creation of a new object. Use StringBuilder to concatenate strings efficiently in a loop.
6. Avoid nested loops when possible
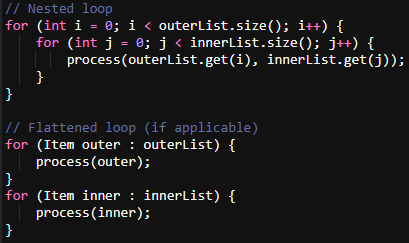
Nested loops can lead to quadratic time complexity (O(n^2)), which is inefficient for large datasets.
Optimized approaches are:
1. Flatten nested loops where possible.
2. Use data structures (e.g., HashMap) to reduce the need for nested loops by leveraging fast lookups.
Reducing Object Creation
Reducing the number of objects created in a Java application can significantly enhance performance. Object creation and garbage collection are costly operations in terms of both CPU and memory usage. Here are some strategies and best practices to minimize object creation and thereby improve performance:
1. Object Reuse
Example of Inefficient Object Creation:
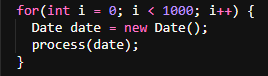
Example of efficient code:
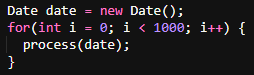
Creating a new Date object in each iteration leads to unnecessary object creation and increases garbage collection overhead. Move object creation before the loop iteration.
2. Flyweight Pattern
Example of Inefficient Object Creation:
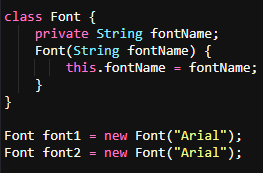
Creating multiple Font objects for the same font name wastes memory.
Optimized with Flyweight Pattern:
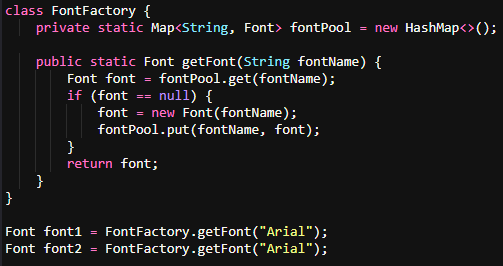
Use the Flyweight pattern to share and reuse objects, reducing memory consumption.
3. Avoid creating Unnecessary Objects in Loops
Example of Inefficient Object Creation in Loops:
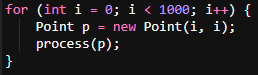
Creating a new Point object in each iteration leads to high memory usage and GC overhead.
Optimized with reused object
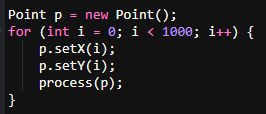
Reuse a single object and modify its state within the loop.
4. String Pooling. Benefit from interned strings to reduce memory usage.
String pooling is a memory management technique where identical strings are stored in a shared pool to avoid redundant storage. This pool, known as the String Pool or interned strings pool, is part of the Java heap. The JVM uses this pool to store string literals and interned strings, ensuring that each unique string is stored only once. When a string literal is created, the JVM checks the String Pool to see if an identical string already exists. If it does, the JVM returns the reference to the existing string. If not, the JVM adds the new string to the pool.

By reusing existing strings, the String Pool reduces memory consumption. This is especially beneficial in applications that use a large number of repeated string literals.
There are two approaches how to add string to the string pool:
1. Use String Literals.

2. Use method intern()

Interning very large strings can lead to high memory consumption in the String Pool, which can negatively impact performance.
Conclusion
Optimizing Java performance and memory management is an ongoing process. By understanding the Java memory model, utilizing profiling tools, tuning JVM options, and applying code-level optimizations, developers can achieve efficient and responsive Java applications. Continuous monitoring and experimentation with different techniques and tools are essential for finding the best solutions for specific applications.